

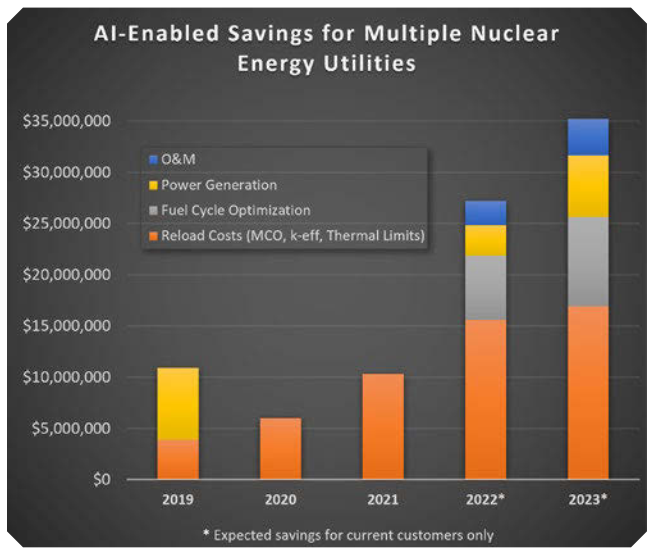
AI技術的應用,短短幾年內節省了數千萬美元,這只是從覆蓋國內所有核電站運營的數千TB字節數據中發現隱藏寶藏的開始。
1、用AI激勵換料設計

2017年,藍波(Blue Wave)AI實驗室和Constellation(前身為Exelon Generation)開始合作,應用植根于AI的技術來解決其中一些核能問題。
Constellation運營著美國最大的核電站(8個發電站有14臺BWR,4個發電站有7臺壓水堆(PWR)),因此擁有大量與這些關鍵挑戰相關的設計、性能和運行數據。
特別是MCO和特征值的可預測性問題是第一個被解決的問題,這兩個問題的解決方案正在被整合到Constellation的重新加載設計過程中。
核能機器學習
首先,機器學習是AI的一個分支,它可以提取復雜問題的答案,這些問題可能通過更傳統的方法難以解決。
當大量數據可用于分析技術問題,或分析基于物理的模型無法解決的異常復雜的非線性問題時,AI尤其有用。
ML中有許多分支,大致可分為幾類:
監督學習;
回歸——用于預測連續變量的回歸,如給定反應堆狀態點的熱極限、MCO或有效性;
分類——用于將元素分配到多個類別(例如,通過確定診斷健康狀態進行設備監控);
無監督學習——用于聚類、異常檢測、降維和特征工程。
ML的基礎是普適逼近定理,該定理保證,如果滿足某些直接條件,人工神經網絡可以以任意精度表示真函數F(x)。更重要的是存在足夠的數據分布,其分布近似于目標系統的預期分布。
試驗數據是用于推斷該函數的數據集,由許多歷史觀測數據組成。函數的輸入或原始特征是反應堆的狀態點x→i給定時刻,而目標是真函數的相應輸出,yi=F(x→i)。
MCO測量、在線特征值或熱極限是上述三個問題的試驗目標。
從根本上說,反應堆狀態點是完整描述給定時刻堆芯狀態所需的所有信息的集合。
在實踐中,我們必須依賴通過測量、設計、設定點或模擬已知的有限信息。
例如,運行參數的測量,如熱功率和堆芯流量、控制棒模式加上切口、燃料和晶格設計,以及堆芯模擬器的大量輸出,共同構成了堆芯的近似表示。
通過足夠的觀察(x→i、yi),控制一個過程的基本功能是可以學習的。
2、關于數據

回到剛剛的問題,每兩年的燃料循環包含數百個每日反應堆狀態點。
雖然每個循環可能包含數百個點,但在一個方面,燃料循環本身可以被視為一個正式點,將與該設計堆芯有關的所有信息編入規定。
因此,將來自多個燃料循環的數據匯集到試驗集中,以了解完整的功能動態至關重要。
對于多個反應堆現場,如果預期基礎功能相似,則可能會合并來自每個機組的數據。
Constellation的大部分沸水反應堆都有六到八個燃料循環的數據,雖然這看起來可能很多(總計數萬個數據點),但ML的典型應用,如圖像識別,需要數百萬個訓練樣本。
已經采用了許多技術來增強數據集,包括用于維持預期分布的數據增強、訓練目標的插值,以及最大限度地利用來自多個站點信息的轉移學習。
這些技術使高精度模型的開發擴展到擁有比其他情況下所需數據更少的反應堆成為可能。
另一個需要克服的挑戰是需要哪些輸入。在核能等非常專業的領域,這往往成為采用AI的主要障礙。
一個純粹的數據科學家可能會以“投入越多越好”的態度來處理這個問題
但是,當輸入的數量與試驗示例的數量相匹配或超過時,這種觀點就行不通了。
在這里,輸入特征空間由來自堆芯模擬器的數萬個束和節點輸出、數十萬個逐針燃料屬性和數十個全局反應堆變量組成。
如果不受約束,所有這些信息都可以用來訓練一個試驗誤差精確為零、預測能力絕對為零的模型!它的效用在哪里?
太多的變量和太多的試驗會導致模型只對試驗集有用,而不是更一般的情況。
當這種情況發生時,模型已經擬合了數據中的噪聲,掩蓋了潛在的功能動態學,并且該模型被稱為過度擬合。
同樣,模型結構的復雜性(例如神經元的數量)也會導致過度擬合的可能性。
當一個模型在新的情況下(例如,新的燃料循環)繼續表現良好時,它被稱為“泛化”良好。
泛化意味著模型能夠很好地捕捉到控制過程的潛在動態,并且在鎖定數據中的隨機噪聲之前停止試驗過程。
訣竅是在(1)輸入特征空間的大小和性質和(2)模型體系結構、建模方法之間找到平衡,并仔細驗證方法,以獲得最具普遍性的模型。
對于MCO來說,答案是通過特征工程和對底層機制的物理理解,將輸入特征空間縮減為MCO關鍵驅動因素的“規范集”。
在這樣做的過程中,輸入特征空間被縮減為幾十個關鍵變量,以捕捉MCO的動態。
這使我們能夠開發具有操作員可以控制的參數的模型,使模型不僅具有預測能力,而且同樣重要的是具有糾正能力。
對于特征值,成功的方法更多地依賴于模型架構的性質,同時保留構成反應堆狀態點的大量輸入特征集合。
通過巧妙地將每個狀態點轉換為通過曝光、空洞、功率等各種“過濾器”查看的反應堆堆芯的三維圖像,我們開發了一種卷積神經網絡架構,該架構已被證明在圖像識別和自然語言處理等任務中非常有效。
3、預測能力
BWR堆芯內束參數的可視化.
與任何創新一樣,結果是其價值或效用的最終仲裁者。
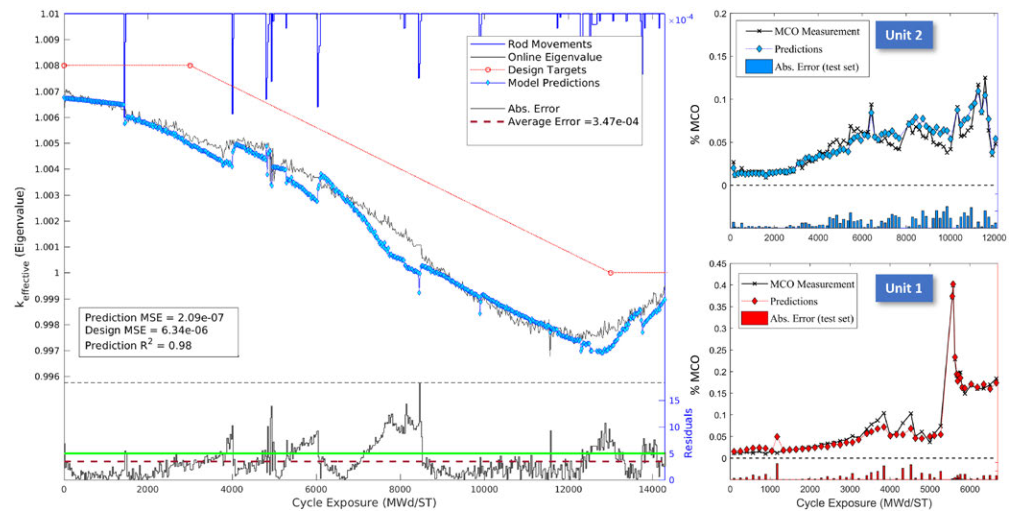
對于MCO,這種預測能力的一個例子在下面的圖表中進行了說明,其中模型預測與兩個Constellation單元的MCO測量值進行了疊加。
在這里,模型預測是從整個周期收集的風險計算中獲得的。
自模型首次部署以來,在過去三年中,該站的平均預測誤差為±0.018% MCO。
這種特殊的性能水平現在僅受到MCO測量不確定度施加的分辨率的限制。采用這一技術的另外10臺BWR也獲得了類似的精確度。
圖中還顯示,與當前實踐狀態相比,特征值模型性能表明,預測不確定性降低了四倍,平均誤差小于±0.0005。
此外,這一性能水平可在整個BWR機組中擴展,當新燃料類型引入堆芯時,模型結構的最新進展顯示出明顯的彈性恢復能力。
從重新裝載設計到周期管理的無縫集成
這些基于AI的預測算法已經變成了基于云計算平臺MCO.ai和特征值.ai,現在完全集成到重新加載過程中。
核心設計的每一次迭代(有很多次迭代)都可以通過平臺運行,以評估設計關于MCO和特征值趨勢的影響。
核心設計人員可以在他們的辦公桌上隨意規劃場景,并探索組合規格、重新裝載批量、裝載模式、反應性控制策略等數百個選項。
這些預測模型是根據堆芯條件和堆芯模擬器輸出得出的輸入特征構建的,所有這些特征都可以在重新加載設計過程的早期階段進行預測。
因此,這些工具采用這些堆芯預測,并在燃料循環開始前一年,為堆芯設計師提供MCO和特征值行為的可靠預測。
通過這種方式,可以優化換料堆芯設計,以減少換料批量和/或濃縮,將MCO降低到規定限值以下,并確保通過更可靠的特征值預測滿足能源需求。
這些新功能不僅限于核心設計,同樣的概念也適用于周期管理戰略評估。
如果發生與計劃運行策略相關的不可預見的變化,如燃料故障、計劃外停機或啟動延遲,則可利用此預測套件分析替代運行場景,并提供用戶友好的比較。
事實上,2019年一座BWR出現了燃料缺陷,需要在整個循環結束時插入功率抑制控制棒,兩個完全插入的控制棒導致MCO比正常情況下大規模增長——MCO從0.05%發生階躍變化到0.4%,在前(該模型以較高的精度預測)單元1 MCO圖中可以看到。
這就提出了一個問題,即在達到不可接受的高MCO水平之前,是否需要在循環中停堆以消除燃料缺陷。
利用MCO.ai,設計了一種運行策略,以在周期結束前將MCO水平保持在程序限制以下,從而避免代價高昂的停機(超過600萬美元)
4、優勢發展
通過與藍波AI實驗室的合作,Constellation在其BWR的兩個長期待解決問題上取得了突破性進展,實現了操作的可預測性。
將ML與堆芯設計和循環管理流程結合使用,可降低燃料成本,降低電廠劑量率,保護電廠資產,避免發電收入損失,并減少返工,從而為業務帶來回報。
藍波AI實驗室和Constellation正憑借這些進步引領行業,并正在尋求其他應用,以改善核電運行和經濟性,短短幾年內節省了數千萬美元,這只是從覆蓋國內所有核電站運營的數千TB字節數據中發現隱藏寶藏的開始。
藍波和Constellation正致力于將這些技術應用于許多領域,解決其他高價值問題,其中包括更精確的熱極限計算、虛擬校準和測量,以及電廠部件的剩余壽命,以實現基于真實狀態的維護策略。
最后,這些見解中的大部分,如對傳感器類型和數量問題的方案,將應用于下一代電廠設計。核工業即將成為無碳能源的天然支柱,AI將加速這一提升,并在一個新的水平上提供更大的發展優勢,我相信這也僅僅只是個開始。
免責聲明:本網轉載自合作媒體、機構或其他網站的信息,登載此文出于傳遞更多信息之目的,并不意味著贊同其觀點或證實其內容的真實性。本網所有信息僅供參考,不做交易和服務的根據。本網內容如有侵權或其它問題請及時告之,本網將及時修改或刪除。凡以任何方式登錄本網站或直接、間接使用本網站資料者,視為自愿接受本網站聲明的約束。
